
In case you are switching to Jira Software from another tool, or simply need to import data from one Jira instance to another, Jira’s native functionalities allows you import issues. Take note that this process is different than the one provided by the Administration Tool for project imports.
Jira can execute an import by connecting directly to tools like Mantis, Redmine, Bugzilla, etc., from Jira’s interface, thanks to dedicated connectors and also execute imports via CSV, Excel, JSON.
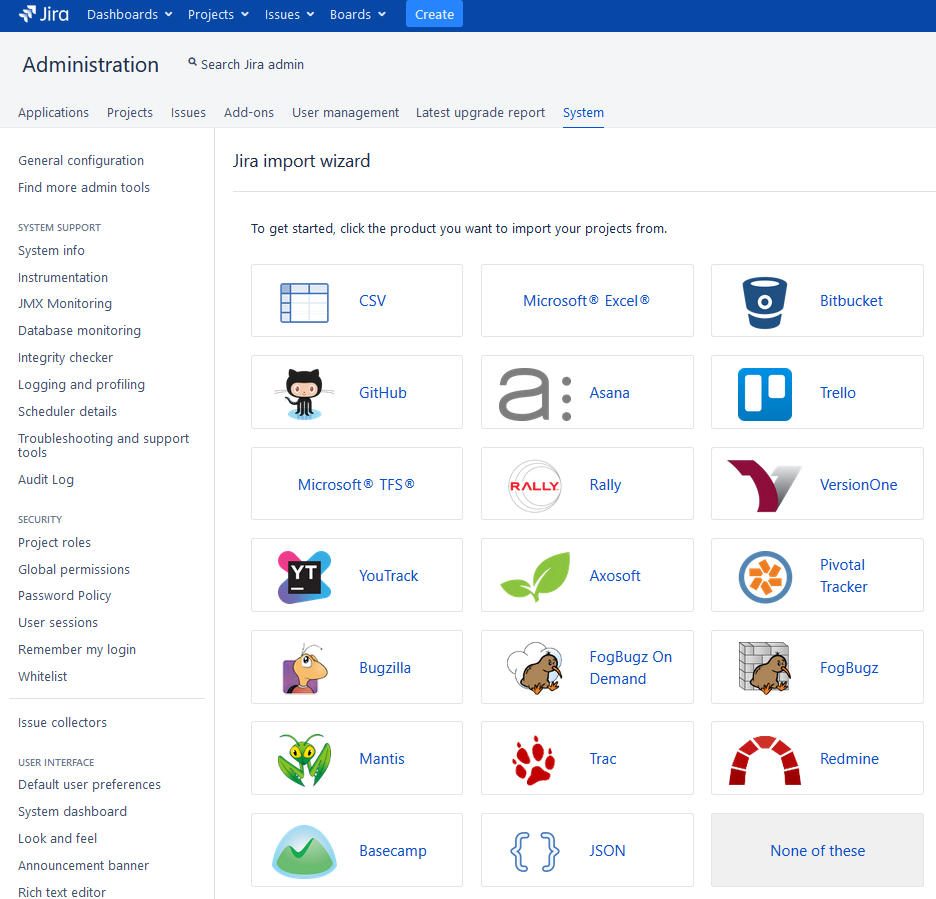
Where to start when importing issues into Jira
First, You must have the necessary permissions needed to retrieve the issues. You will also need to have information regarding how the source tool will connect, such as port numbers, database names, etc.
On the target Jira instances where the imports will go, you need to ensure you are an administrator. Importing bulk issues into the tool can lead to significant consequences, so before the import it is best to ensure all actions and behaviors are configured properly in Jira.
Finally, you’ll need to know the table in which the fields will correspond for the import. If the source environment is not identical, you will need to map the field values – especially for workflows, resolutions and priorities. It is highly recommended that this type of import is done in a test environment.
In case the import is from a file, modifying the source file may be necessary to allow for the import’s execution. Make sure you read the entire process before you start!
Import from Mantis
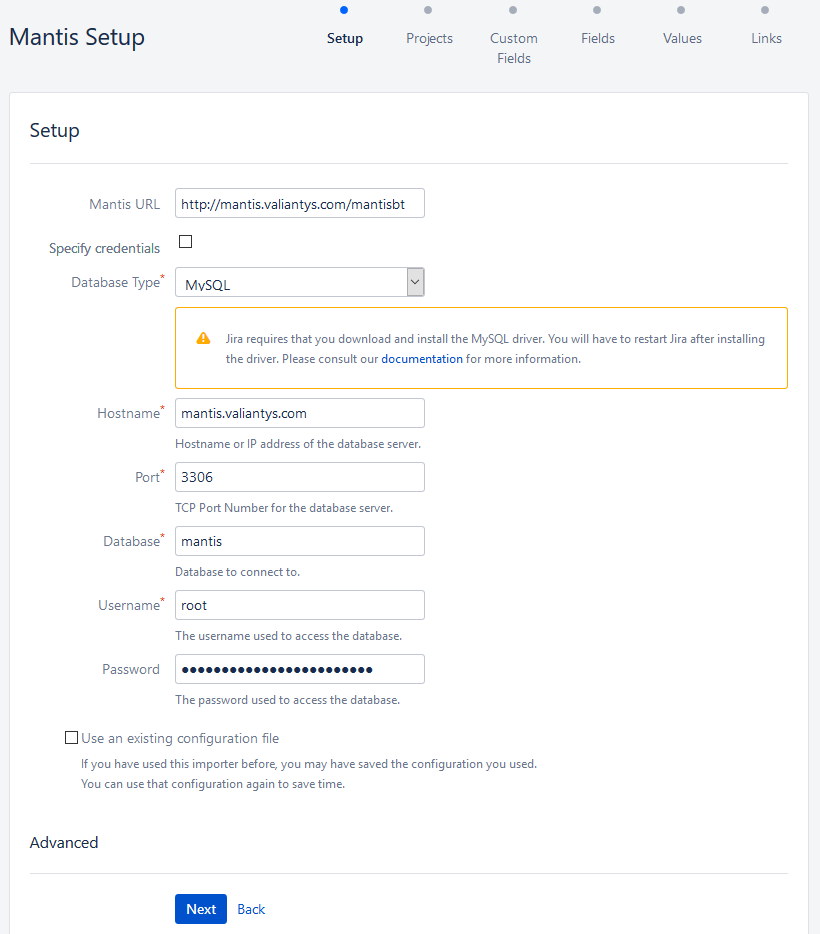
An import from Mantis is done by accessing the tool’s database, so logically you’ll need to be able to connect to it.
Take note: If Mantis uses MySQL but Jira doesn’t, the connector library will obviously be missing in Jira. Remember to add it and restart the instance to ensure that it is accounted for.
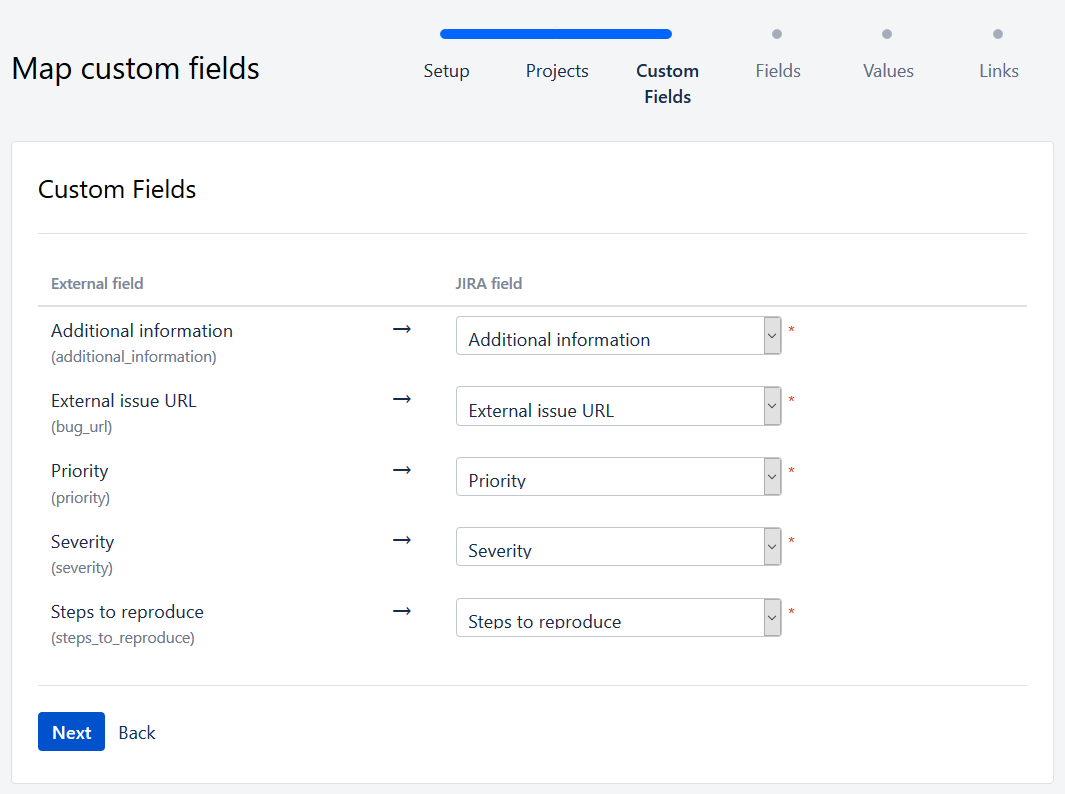
Once the configuration is done, the tool will ask you to select the target project. Once the selection is made, you can start mapping the fields. You’ll need to map the information stored in the source tool and the Jira fields. It is very important to respect best practices. Try to make the most of the existing fields, and also check the scope of these fields in your set-up are used by the target project.
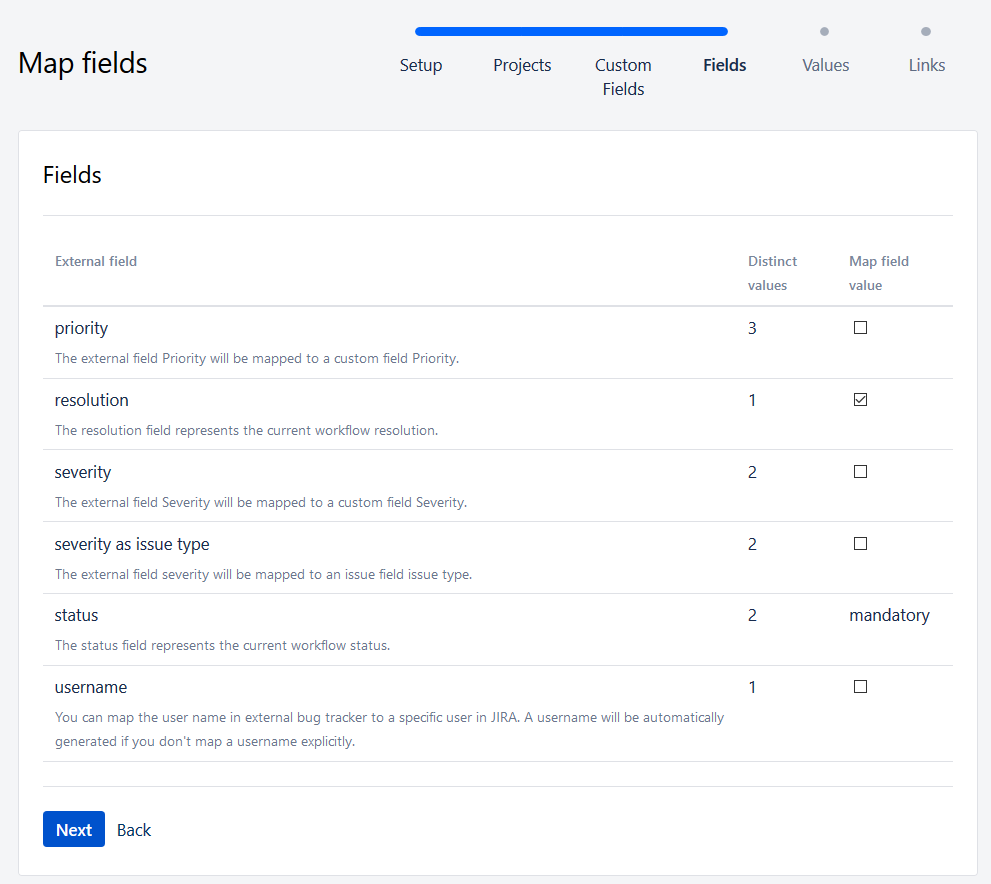
On the following screen, you will be asked if you want to transfer the data after the mapping. You’ll also need to fill in the target values.
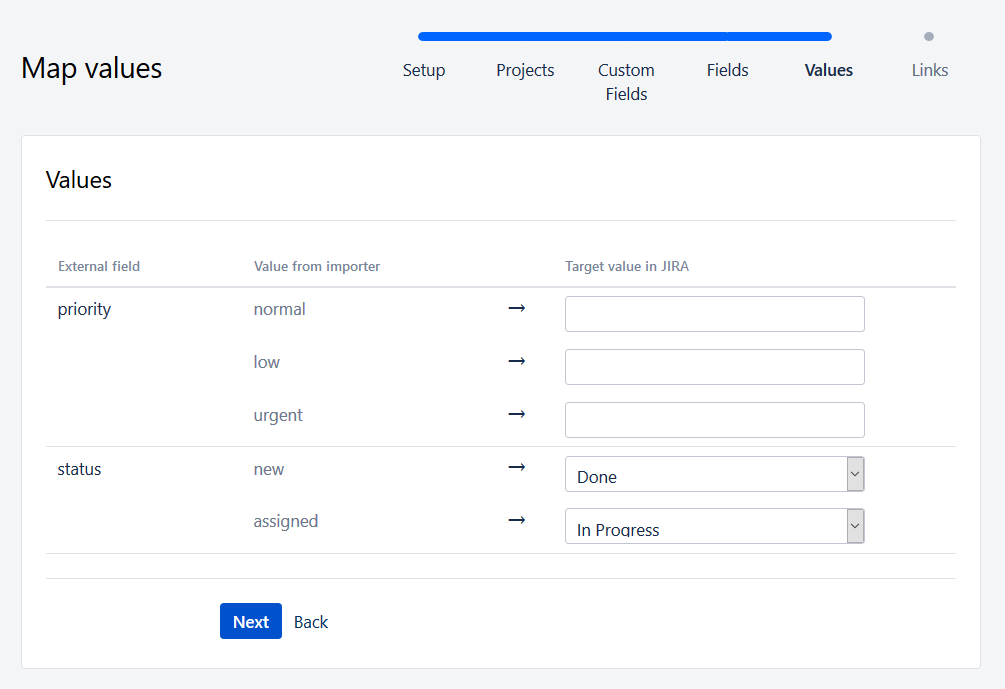
All you have to do is match the types of links, run the import, and then start using your imported tickets in Jira.
Import Jira issues from a CSV file
Importing from a CSV file is a bit more constraining that from the source tool via a connector. In this case, it is necessary to make a more detailed capture in terms of the mapping. In Jira, values such as the description, the type of issue, the priority, the reporter, etc., must be defined so that the ticket can exist in the new Jira instance. This doesn’t take into account the mandatory fields defined in the set-up.
The process for the import changes depending on the source file.
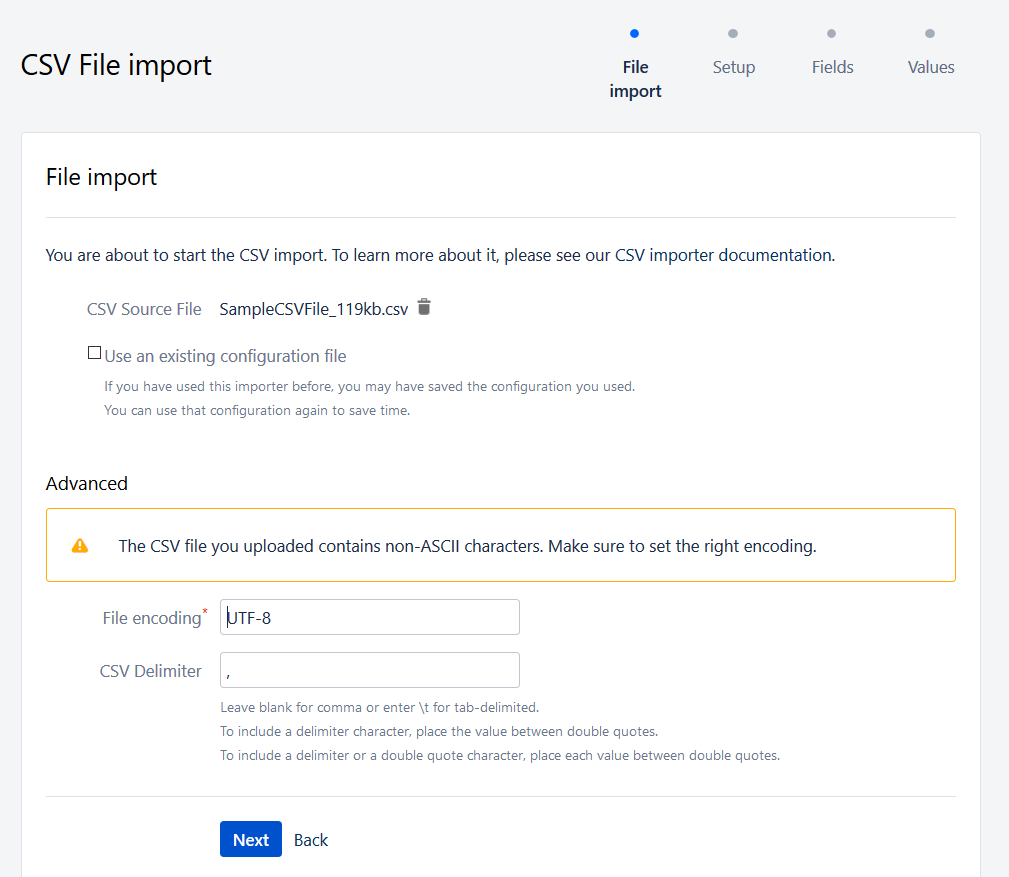
Choose a CSV file. Then you’ll need to choose the encoding – a significant point if you do not want strange characters after the import – then choose the separated value.
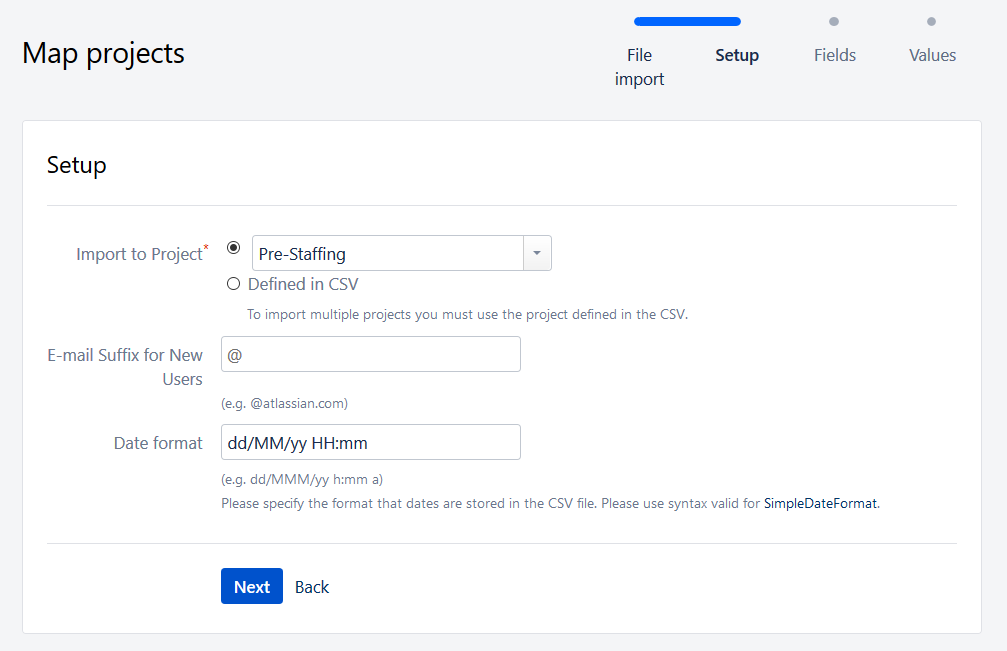
Assigning tickets can be done in a single project, or many, depending on your needs and the content of the source file. The project(s) must first exist in Jira. The format of the date will be used for parsing. Please ensure that it follows the original definition in your import file. If some columns do not have the same format, you’ll need to rework the file so everything is aligned.
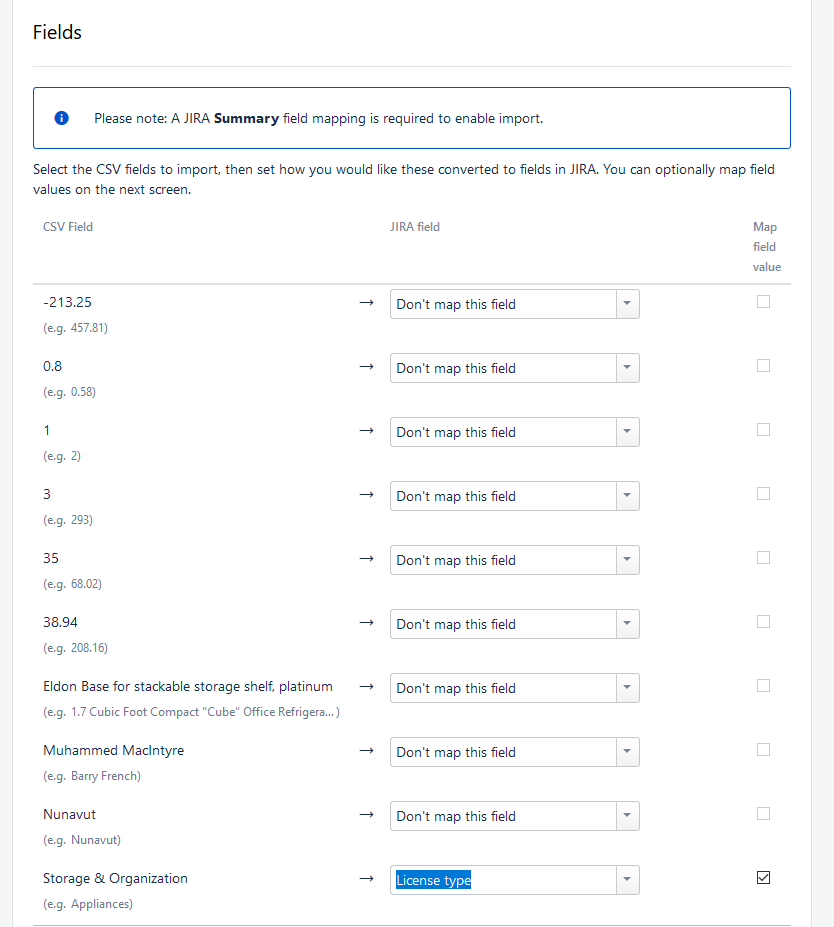
The mapping(s) are done this time in the same screen. It should be noted that if the mandatory fields / types are not entered, it will not be possible to continue the import.
In case you want to import several comments or several attachments per issue, you must define this (if this isn’t already done), one column per element in the CSV file.
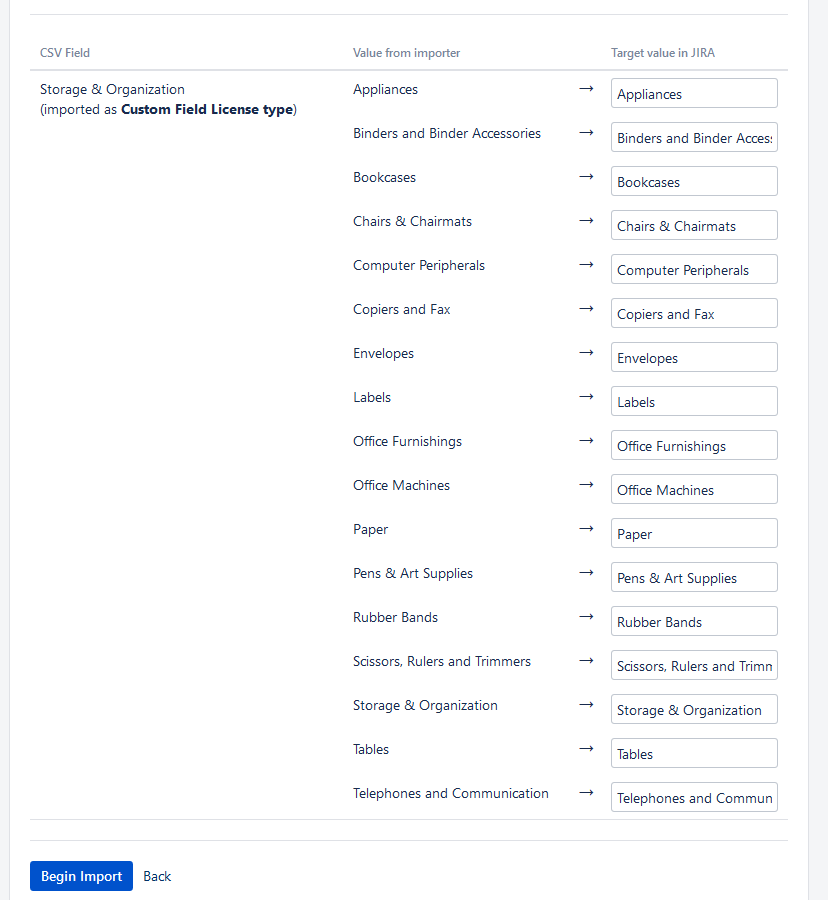
Finally, the last step consists of assigning values, and then you can finish the import.
A few tips for facilitating the migrations of your imported issues
- Play around on the test environment first!
- In the event of a discrepancy between the source issue and the Jira configuration, do not hesitate to contact the tool administrators / the project managers to help review the import configuration.
- You must fill in the user name (rather than their actual name).
- Check that the Date, Number, or Select list fields are in a uniform format and are correct.
- Map the value of the fields for type Select List (to avoid creating new values during the import) along with any fields where there are any doubt.
- Open the CSV file with a classic text editor, such as Notepad, to make sure the raw data is in the correct format.
- At the end of the import, save the logs and the configuration file. This will help identify any potential anomalies as well as allow you to reuse your configuration file for future imports.
Your turn to import issues into Jira!
As you can see from the step-by-step tutorial above, importing issues into Jira isn’t very technically complicated, but it does require a high level of attention to detail. How the data is formatted and verified is key. In order to identify any blocking points and / or anomalies, it is strongly recommended to run the first import on a testing environment before reproducing it in production.
Go forth and import your issues! Know that if you ever run into any problems, our highly experienced Atlassian certified consultants can provide you with assistance. We talk more about this in the article below:
Read the article
For more tips and best practices on Jira, refer to more of our blog articles here.


